This is the first post in a new series I’m writing on Azure’s Application Insights (AI) service. The goal of the series is to walk through some of the basics for monitoring your Azure hosted services with Application Insights. We will cover topics like instrumentation, monitoring dashboards, and paging alerts.
In this post we have a look at code instrumentation: What is it? What are SLIs? How do we use the Application Insights client libraries? What are some instrumentation best practices?
Series links
Part 2: Azure Application Insights series part 2: How to create application monitoring dashboards in Azure.
Part 3: Azure Application Insights series part 3: How to configure monitoring alerts.
What is instrumentation?
Instrumentation is code added to an application that allows us to monitor the application’s performance, debug errors, track metrics, and write trace information.
Instrumenting your application is helpful because it provides more insight into how the application or service is functioning (beyond a simple healthbeat response code). Instrumentation becomes crucial in distributed systems to track requests processing through the system.
Service level indicators
How do we know what to instrument? Or which parts of our application should expose metrics? Before you sit down to add any instrumentation code you will need to define some service level objectives and service level indicators that matter for your environment.
- Service Level Indicators (SLI): these are the individual measurements or metrics to track. Examples can include: request latency, error rate, availability, throughput, storage durability, etc.
- Service Level Objectives (SLO): these are the target values or ranges for a service level that is measured with an SLI. For example: search latency should be less than 100ms.
You should have a small number of SLOs that cover core user scenarios. Think about the perspective of the end-user when defining these. Keep them simple and measurable.
Deploy an Application Insights service
The obvious prerequisite here is that we need to have a deployed instance of the Azure Application Insights service. Deploy one to your Azure subscription if you haven’t already.
I recommend taking the infrastructure-as-code route and deploying your Application Insights resource via Azure Resource Manager (ARM) templates: instructions.
After deployment take note of the instrumentation key. It can be retrieved through code by calling the Azure APIs or viewed from the Azure Portal directly on the overview tab of the resource:
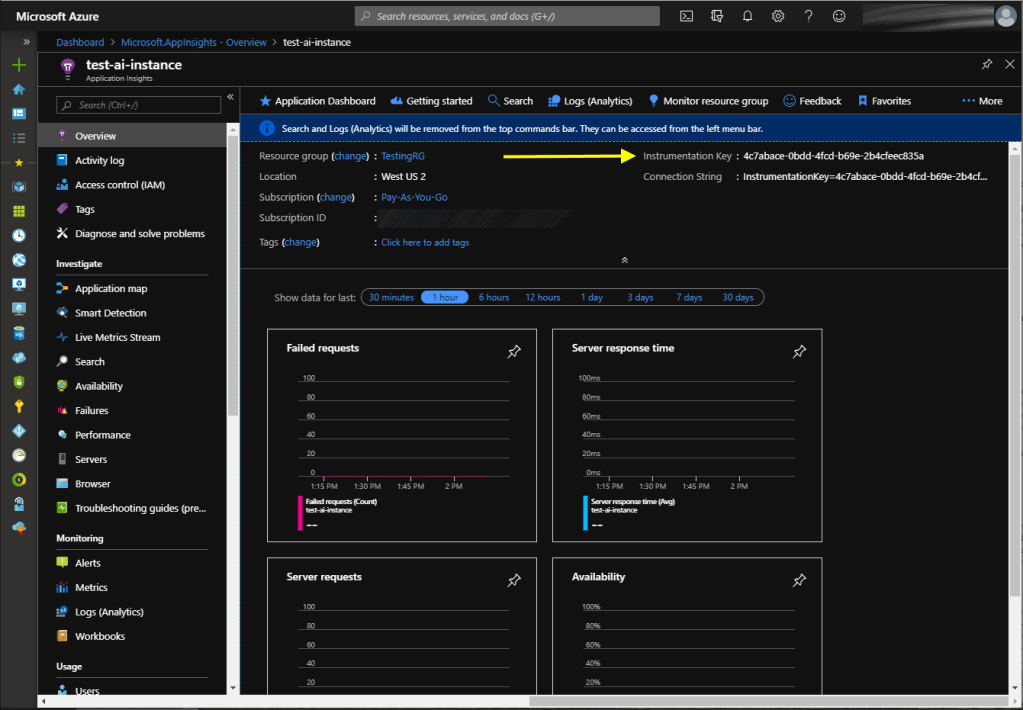
Note: The instrumentation key is not considered a secret value. It is safe to check this value into source control and/or use it as a configuration value in public client applications.
Sending instrumentation data with Application Insights client libraries
Now its time to add the Application Insights client library to our application. Microsoft provides several of these packages for different languages. The library provides a thread-safe wrapper class around the calls to send the instrumentation (telemetry) data to Azure.
I’m working with a sample .NET Core console application, so I install the Microsoft.ApplicationInsights nuget package from the Package Manager window or console.
The following is a C# code sample that uses .NET Core’s dependency injection to configure a TelemetryClient class, and then use it send instrumentation data (a ‘hello world’ message) to our Application Insights service in Azure:
// build a services collection
var servicesCollection = new ServiceCollection();
servicesCollection.AddSingleton<TelemetryClient>();
// build the service provider from the collection
// this is used in dependency injection for .NET core services.
var serviceProvider = servicesCollection.BuildServiceProvider();
// configure the AI client by adding an instrumentation key
// you can omit this step if you have set your InstrumentationKey via environment variable.
serviceProvider.GetService<TelemetryClient>().InstrumentationKey = "-key-";
// when you need to log some data, pull the AI client
// from the service provider and call the .Track() methods.
// this example sends a trace message.
var aiClient = serviceProvider.GetService<TelemetryClient>();
aiClient.TrackTrace("Hello world");
// Telemetry events are cached locally and sent in batches.
// Calling .Flush() will force any pending events to send immediately.
// This is not normally called unless you are in a single-threaded context which is about to exit before sending the data.
aiClient.Flush();After running this code in a .NET Core console application, we have our first piece of telemetry data logged to the Application Insights service. Clicking on the individual event reveals additional properties about the client and where the telemetry was sent from.
Note: Telemetry takes a few minutes to show up in the Application Insights service in Azure. Data is not immediately available.

The TelemetryClient class exposes different methods to track the various types of instrumentation data we want to send. For example sending metrics with TrackMetric(), or exceptions with TrackException(). For detailed instructions on how to use each one correctly, visit this reference article.
Instrumentation best practices
1. Use the built-in Azure service metrics to capture basic SLIs.
Let’s assume we have deployed an Azure App Service and we want to instrument the code to capture service level indicators (SLIs). Before you start writing custom telemetry or metrics, be aware that the Azure platform provides loads of SLIs out of the box for each Azure service type.
For example Azure App Service has over 30 SLIs available at the time of this writing (see here). This means you don’t have to manually calculate and report on Average Response Time, since there is already an SLI available for that. Review the monitors available for the service before you do anything else.
2. Use telemetry correlation features.
When working with distributed systems like microservices, it’s easy to lose the full context of a request when examining a single piece of telemetry data. Application Insights supports telemetry correlation features that allow you to tie a string of related sub-activities together and associate them as a single larger request.
This is really helpful for seeing how a request flows through the entire system and for debugging scenarios. More information can be found here.
3. Use a single Application Insights service instance.
Instead of having multiple separate Application Insights services per application deployed in Azure, just deploy a single service per application. The reason for this is that the telemetry correlation features only work within a single Application Insights service, and not across multiple Application Insights services.
The data volume that a single Application Insights service can ingest is pretty impressive, so this usually works for all but the most extreme usage scenarios.
4. Use telemetry initializers to enforce consistency.
Telemetry initializers can be used to filter or pre-process telemetry events before they are sent. For example you want to make sure every piece of telemetry sent has some custom properties assigned– like a specific service and sub-component name, or additional custom tags.
This enforces that all telemetry gets processed in the same manner and application code that calls the TelemetryClient.Track() operations don’t have to remember to add those properties. More information is available here.
5. Keep custom telemetry event and metric names stable.
I recommend using TelemetryClient.TrackEvent(“MyCustomEvent”) to log custom events related to important user behavior or system events. For example a user completed a specific transaction type, or a specific unrecoverable error condition was reached that requires on-call support intervention.
We can drive alerts and metrics from specific event names, so we should treat them as string constants. I also find it helpful to add pinning unit tests that ensure the value of the event name constants don’t change. The reason for this is that changing the event names could impact existing alerts or metrics in use in downstream resources (like dashboards or incident management systems).
6. Use events to track progress through multi-stage transactions.
Logging App Insights events at each stage of a multi-stage transaction is really helpful for debugging. This is used in conjunction with #2 (correlation IDs).
For example lets assume we have an multi-stage transaction for registering a new user. It performs a few actions like creating a new user account record in the database, sending a new user email confirmation, etc.
Write up a table of the transaction steps (example below) and then log successful and failed events that are essentially checkpoints along the transaction.
| Order | Description | Successful Events | Failure Events |
| 1 | Create user account record | NewUserCreated | NewUserCreationFailed |
| 2 | Send new user registration email | NewUserEmailSent | NewUserEmailFailed |
| 3 | Save user profile settings | NewUserProfileSet | NewUserProfileSetFailed |
| 4 | Apply promo credits | AppliedPromoCredits | PromoCreditApplyFailed |
Paired with the correlation ID, we could search on this ID and find that the events logged for that transaction easily pinpoint the exact failed stage.
7. Supply custom properties for more context.
The App Insights client Track() methods provide an optional parameter that allows you to specific a custom property bag (dictionary) (see here). You can leverage this to provide more application specific context about telemetry you send.
For example you may want to pass a customer ID, or an order number into the properties for an event. This makes it easier to search for relevant events when debugging.
8. Leverage the dependency tracking features.
If we leverage TelemetryClient.TrackDependency() on calls to other services or APIs, then Application Insights can show us some rich data on the availability and latency of those downstream resources. Some dependencies are even tracked automatically. See more information here.
9. Use multi-dimensional metrics to enable better charts.
If you are designing custom metrics for your application, try to use multi-dimensional metrics instead of flat metrics. Let’s take a look at an example of each to see the difference:
// track a flat metric (the number of signed-in users)
client.GetMetric("SignedInUsers").TrackValue(17);
// track a multi-dimensional metric (number of active users, by type).
var signedInUsers = client.GetMetric("SignedInUsers", "UserType");
signedInUsers.TrackValue(3, "PowerUsers");
signedInUsers.TrackValue(14, "StandardUsers");This is a simple example but it helps us down the road when we start building charts/graphs. Instead of a single lined chart with the number of signed-in users, we can have a chart with multiple lines plotting the different user types of signed-in users.
Conclusion
That concludes the first post of the Application Insights series. Stay tuned for the next post where we look at creating Azure Dashboards for telemetry data.

3 thoughts on “Azure Application Insights series part 1: How to instrument your application code for monitoring”